Optimizing Java - 하드웨어/운영체제
1. 근간 기술을 배워야 하는 이유
무어의 법칙이 한계에 다다르고 저렴해진 트랜지스터를 활용해 성능 향상을 꾀하기 위해 하드웨어는 매우 복잡해졌다. 소프트웨어도 이에 맞춰 함께 복잡해져 하드웨어를 잘 알지 못해도 이러한 성능 향상을 누릴 수 있었다. 하지만 성능 향상을 진지하게 고민하고 있다면 이렇게 복잡해진 근간 기술에 대한 이해가 있어야 한다.
2. 최신 하드웨어
1) 메모리 캐시
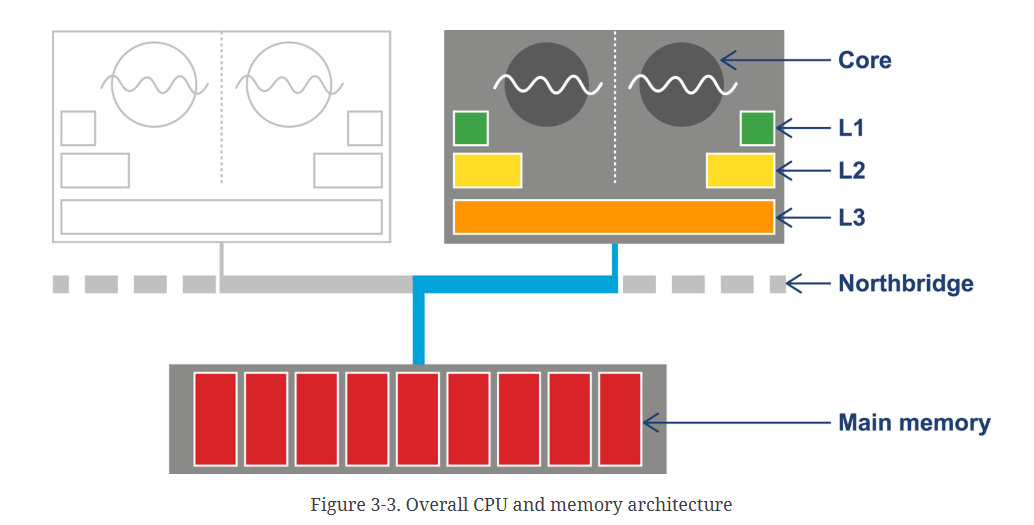
하드웨어의 발전으로 CPU의 클록 속도가 증가하니 처리 속도는 빨라졌지만 메인 메모리의 속도는 여전히 느려 CPU가 다 처리되었음에도 메모리를 기다려야 하는 상황이 발생하였다. 이 상황에서 메모리 캐시가 등장하였다.
메모리 캐시는 계층 구조를 가지고 있으며 가장 느린 L3 캐시조차 메인 메모리에 비해 아주 빠르다. 이를 사용함으로써 데이터 액세스 시간을 줄여 CPU의 사용률(성능 지표)을 높이고 프로세서의 처리율은 현저히 개선되었다.
(1) 캐시 일관성 프로토콜
캐시 중 L1과 L2 캐시는 다른 코어와 공유하지 않는다. 다른 코어와 공유하지 않다면 두 개의 코어가 하나의 데이터를 본인이 가지고 있는 캐시에서 각각 수정하면 하나의 데이터에 대한 값이 코어마다 달라질 수 있다는 문제가 있다. 이를 해결하기 위해 캐시 일관성 프로토콜(MESI 프로토콜)을 사용한다.
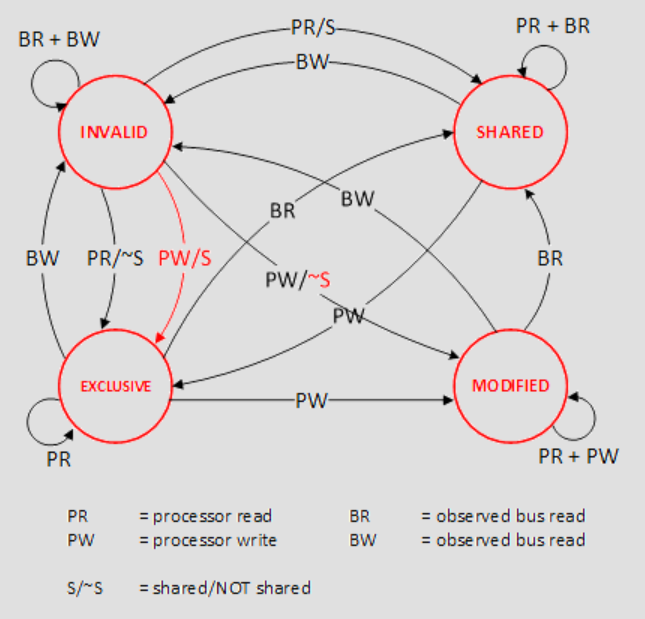
- Modified: 데이터가 수정된 상태
- Exclusive: 해당 캐시에만 존재하고 메인 메모리 내용과 동일한 상태
- Shared: 둘 이상의 캐시에 데이터가 들어 있고 메모리 내용과 동일한 상태
- Invalid: 다른 프로세스가 데이터를 수정하여 무효한 상태
상태 전이에는 많은 상황들이 있지만 간단하게 MESI 프로토콜이 하는 일을 요약하면 다음과 같다.
- 둘 이상의 캐시에 존재하는 데이터(Shared)가 수정이 되지 않은 경우 유효한 데이터로 사용할 수 있다.
- 둘 이상의 캐시에 존재하는 데이터(Shared)가 수정이 된 경우(Modified) 수정한 캐시 외에 다른 캐시에서는 유효하지 않은(Invalid) 데이터가 되어 사용할 수 없다.
- 하나의 캐시에만 존재하는 데이터(Exclusive)가 수정이 된 경우(Modified) 다른 캐시에 알리지 않는다.
(2) 메인 메모리와 캐시 동기화
캐시에 데이터의 수정이 있을 때마다 메인 메모리와 캐시를 동기화하는 과정은 꽤 비효율적이다. 이를 해결하기 위해 write-back 방식이 등장하였다.
캐시에 데이터를 수정할 때마다 메인 메모리와 동기화하는 것이 아니라 나중에 해당 수정된 데이터를 다른 캐시에서 저장할 때, 캐시에서 제거하기 전과 같은 상황에만 메인 메모리와 동기화하므로 쓰기 지연 효과로 성능을 향상할 수 있다.
(3) 캐시 예시에서 확인하는 JVM 성능 측정
1
2
3
4
5
6
7
//test1
for (int i = 0; i < testData.length; i++)
testData[i]++;
//test2
for (int i = 0; i < testData.length; i += 16)
testData[i]++;
이러한 근간 지식 없이 섣부른 직감만으로는 JVM 성능 문제를 잘못 판단하기 쉽다. 근간 지식이 없다면 test2는 순회하는 데이터가 16배 적으므로 시간이 16배 적게 소요될 것이라고 착각할 수 있다.
하지만 실제 실행 시 test1과 test2는 거의 비슷한 시간을 얻을 수 있다. 이는 캐시의 순차 접근, 랜덤 접근과 관련한 문제로 이러한 근간 지식이 있어야 실험 결과에 대한 보다 정확한 분석을 할 수 있다.
(2) 최신 프로세서의 특성
메모리 캐시는 향상된 하드웨어의 성능(특히 트랜지스터 위주의)을 활용하는 가장 좋은 예시이고 이 외에도 성능을 활용하기 위한 여러 기술이 등장하였다.
(1) TLB(Translation Lookaside Buffer)
가상 메모리를 활용하면 전체 프로세스에 필요한 데이터 중 바로 사용할 데이터는 메인 메모리에 그렇지 않은 데이터는 디스크에 저장함으로써 더 많은 프로세스들을 실행할 수 있다. 이 때 가상 메모리를 물리 메모리와 매핑하기 위해 페이지 테이블에서 정보를 저장한다.
이때 페이지 테이블은 메인 메모리에 저장되는 경우가 많고 계층이 여러 개인 페이지 테이블인 경우 탐색에 더 오랜 시간이 걸린다. TLB는 메인 메모리보다 고속인 캐시로 프로세스의 실행 속도에 맞추어 빠르게 물리 메모리로 변환할 수 있다.
(2) 분기 예측(Branch Prediction)
하나의 프로세스를 여러 개의 단계로 분리하여 각각의 단계를 수행하는 하드웨어가 존재하여 여러 개의 프로세스를 처리할 수 있다. 명령어 인출과 관련된 하드웨어는 프로세스 1번의 명령어 인출을 수행하고 명령어 수행과 관련된 하드웨어는 프로세스 2번의 명령어를 수행함으로써 여러 프로세스가 동시에 수행될 수 있다. 이 과정에서 조건문이 있는 경우 조건문의 결과에 따라 명령이 달라지게 된다. 분기 예측은 가능성을 평가하고 분기 결과를 미리 예측하여 해당 명령어의 일부 파이프라이닝 단계를 수행하는 기법이다.
(3) 하드웨어 메모리 지원
JIT 컴파일 과정에서 동일한 결과가 보장된다면 최적화를 위해 코드의 실행 순서를 변경할 수 있다. 하지만 다른 스레드와 동시에 실행되고 해당 코드를 다른 스레드가 접근할 수 있다면 실행 순서가 바뀌게 될 때 결과가 달라질 수 있다.
하드웨어의 종류에 따라 코드의 실행 순서를 변경할 수 있는 경우와 그렇지 않은 경우의 분류가 다르다. 예를 들면 다음과 같이 서로 영향이 없는 변수 저장 코드는 ARM에서는 순서를 바꿀 수 있지만 AMD64에서는 허용하지 않는다.
1
2
myInt = otherInt;
intChanged = true;
3. 운영체제
성능 향상에서 CPU와 메모리의 비중은 매우 크다. 운영체제는 리소스, 특히 CPU와 메모리를 관리하므로 운영체제에 대해 아는 것은 프로그램 성능 향상에 대한 인사이트를 얻을 수 있다.
1) 스케쥴러
프로세스 스케쥴러는 프로세스의 CPU 사용을 통제한다. 스케쥴러는 프로세스가 일정 할당 시간 이상으로 실행되면 프로세스의 실행을 중단하고 대기 상태로 변경한다. 만약 대기하고 있는 프로세스가 적다면 길지 않은 시간 내에 다시 할당이 될 것이고 그렇지 않다면 많이 기다려야 한다.
이는 실행 중인 다른 프로세스는 한 프로세스의 성능 측정에 영향을 줄 수 있다는 말이므로 이를 잘 고려해야 한다.
2) 시간 문제(실행 환경에 따른 성능 최적화)
동일한 기능이더라도 OS마다 해당 기능을 호출하는 시스템 콜의 구현 방식이 다르기 때문에 약간의 성능 차이는 발생할 수 밖에 없다. 하지만 자바는 이러한 시스템 콜을 JNI라는 자바 네이티브 메서드로 한번 더 추상화한다. 이러한 자바 네이티브 메서드는 운영체제에 따라 구현 방식이 달라지기 때문에 실행 환경에 따라서도 기존 c에 비해 더욱 성능이 달라질 수 밖에 없다.
(1) 맥OS에서 javaTimeMillis의 네이티브 메서드 구현
1
2
3
4
timeval time;
int status = gettimeofday(&time, NULL));
assert(status != -1, "bsd error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
(2) Window에서 javaTimeMillis의 네이티브 메서드 구현
1
2
3
4
5
6
7
if (UseFakeTimers) {
return fake_time++;
} else {
FileTime wt;
GetSystemTimeAsFileTime(&wt);
return windows_to_java_time(wt);
}
3) 컨텍스트/모드 스위칭(Context/Mode Switching)
인터럽트 등으로 한 프로세스를 종료하고 다른 프로세스로 교체하거나 하나의 프로세스 내에 시스템 콜의 호출 등으로 모드 스위칭이 발생하는 경우 캐시를 온전히 활용할 수 없다. 컨텍스트 스위칭 과정에서는 그동안의 스택 상태와 스레드 실행 명령을 교체하게 되고 모드 스위칭 과정에서는 TLB를 비롯한 일부 캐시가 플러시되기도 한다. (알고보니 모드 스위칭 과정에서 TLB를 비롯한 캐시를 플러시하는 이유가 보안과도 관련되어 있었고 이는 Meltdown 취약점과도 연관되어 있었다[참고])
따라서 빈번한 컨텍스트 스위칭과 모드 스위칭은 성능 저하를 야기할 수 있다.
(1) vDSO(virtual Dynamically Shared Object)
vDSO(가상 동적 공유 객체)는 리눅스에서 사용자 영역에 존재하는 메모리 공간으로 모드 스위칭없이 일부 시스템 콜을 호출할 수 있다. 예를 들어 시간을 호출하는 시스템 콜은 단순히 커널 영역의 데이터만 가져오므로 이를 위해서 커널 모드로 스위칭하는 것은 비효율적인 과정으로 볼 수 있다. 따라서 커널 공간에 있는 데이터를 단순히 읽기만 하는 경우 vDSO는 커널 공간에 있는 데이터를 유저 공간으로 매핑해주어 시스템콜의 호출 없이 vDSO에서 바로 꺼내어 사용할 수 있다.
Reference
https://www.scss.tcd.ie/jeremy.jones/VivioJS/caches/MESIHelp.htm