Optimizing Java - 자바 언어의 성능 향상 기법
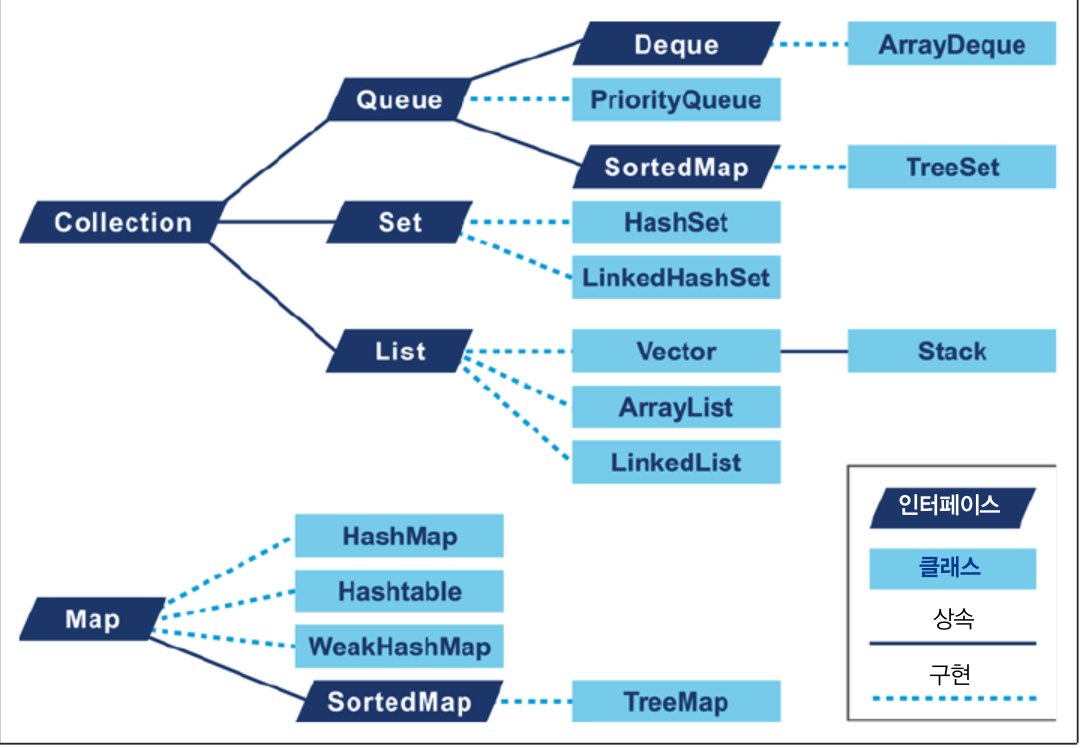
1. 컬렉션 최적화
대부분 프로그래밍 언어는 두가지 컨테이너를 제공한다.
- 순차(sequential) 컨테이너: 인덱스로 표기한 특정 위치에 객체를 저장(List)
- 연관(associative) 컨테이너: 객체 자체를 이용해 컬렉션 내부에 저장할 위치를 결정(Map)
컨테이너의 메서드가 정확히 작동하려면 저장할 객체가 호환성(comparability)와 동등성(equivalence) 개념을 지니고 있어야 한다. 이는 hashcode(), equals()로 구현된다.
자바 언어의 한계로 순차 컨테이너라도 순차적으로 저장되는 데이터는 객체 자신이 아닌 레퍼런스이다. 따라서 실제로 객체 자체는 순차적으로 위치하지 않아 C/C++ 만큼의 성능을 얻을 수는 없다. 이를 해결하기 위해 값 타입을 도입하려는 시도가 있다.
1) List 최적화
자바에서 List는 ArrayList와 LinkedList 두가지 기본 형태로 나타낸다.
“Stack은 거의 쓸데없는 추가 로직만 갖고 있고 Vector는 완전히 Deprecated된 클래스이다.”
Vector는 모든 메서드에 synchronized를 사용하기 때문에 간단한 조회도 동기화로 인해 성능 저하가 발생한다. Stack 또한 이러한 문제가 있기 때문에 Stack 대신 Deque 사용을 권장출처
(1) ArrayList
ArrayList는 고정 크기 배열에 기반한 리스트이며 배열이 꽉 차면 더 큰 배열을 새로 할당한 다음 기존 값을 복사하는 크기 조정이 수행된다. 이 때 초기 용량값을 생성자에 전달하면 크기 조정을 하지 않아도 된다. 성능에 민감하다면 크기 조정 작업의 비용과 크기 조정이 가져다 주는 유연성을 잘 저울질 해야 한다.
(2) LinkedList
LinkedList는 동적으로 증가하는 리스트이다. 이전 원소와 이후 원소를 바라보는 이중 연결 리스트로 구현되어 있다.
(3) ArrayList vs LinkedList
| 항목 | ArrayList | LinkedList | 설명 |
|---|---|---|---|
| 특정 인덱스 접근 | O(1) | O(N) | LinkedList는 처음부터 해당 인덱스만큼 원소를 방문해야 한다 |
| 원소 삽입/삭제 | O(N) | O(1) | ArrayList는 삭제하거나 추가할 경우 오른편 원소를 모두 이동해야 한다 |
LinkedList의 고유 기능이 꼭 필요한 경우가 아니고 랜덤 액세스가 필요하다면 ArrayList를 권장한다. 이 때 ArrayList는 가급적 미리 크기를 지정해서 다시 조정하는 일이 없도록 하는 게 좋다.
2) Map 최적화
| 설명 | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| 삽입, 삭제, 조회 | 평균: O(1), 최악: O(n) | 평균: O(1), 최악: O(n) | O(log n) |
| 활용 | 일반적인 키-값 관리 | 입력한 키-값의 순서 또는 접근 순서가 필요할 때(LRU 구현) | Map의 범위 검색, 키 정렬이 필요할 때 |
(1) HashMap
해시 테이블에 기반한 연관 배열이다.
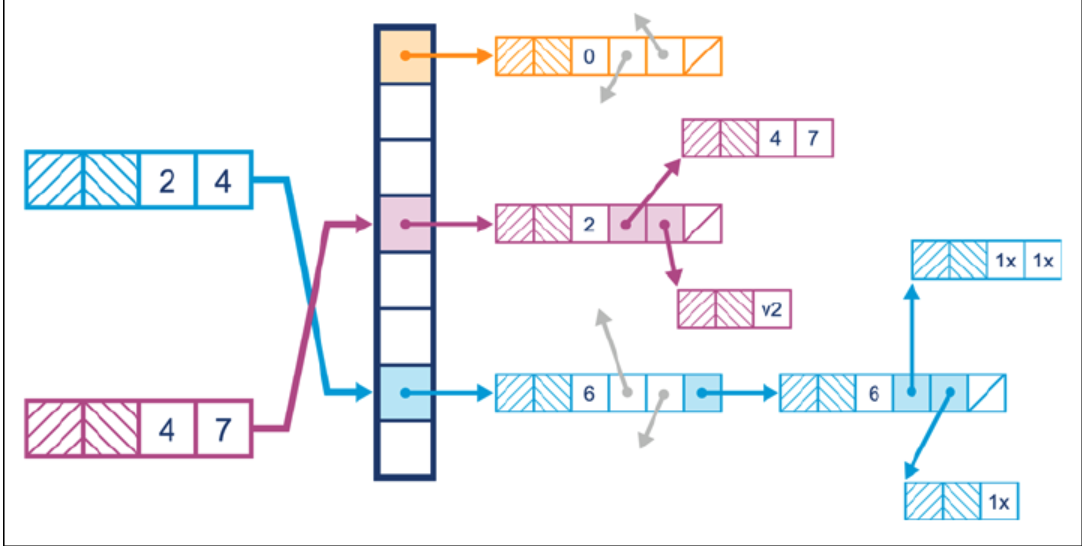
중앙의 리스트는 해시 버킷으로 해시값과 실제 객체가 매핑된다. hashCode()로 해시 버킷의 위치를 찾고 만약 동일한 해시값인 객체가 여러개라면 equals() 메서드로 실제 객체를 찾는다. 동일한 해시값인 객체는 LinkedList나 트리 자료구조로 관리한다.
하위 버전의 자바에서는 해시 버킷의 인덱스 결정 방식이 단순하여 해시 코드의 상위 비트가 인덱스 계산에 사용되지 않는 경우가 발생하였다. 이 때에는 해시 충돌 가능성이 증가한다. 하지만 최신 버전은 상위 비트를 무조건 반영하도록 설계하여 좀 더 골고루 분포되도록 변경되었다.
이 해시 버킷 또한 고정 크기로 객체가 많아지면 버킷 용량을 두배로 늘린다. 따라서 ArrayList와 비슷하게 용량을 2배 늘리고 저장된 데이터를 다시 배치한 다음 해시를 다시 계산하게 되는데 이를 재해시(rehash)라고 한다. 그러므로 ArrayList처럼 저장할 데이터 양을 예측할 수 있으면 고정 크기로 할당하는 것이 좋다.
자바 8 이전은 동일한 해시값을 가진 객체를 LinkedList로 관리하였는데 이후에는 TREEIFY_THRESHOLD만큼의 객체 수가 모이면 트리로 변경한다.
(2) LinkedHashMap
HashMap의 서브 클래스로 이중 연결 리스트를 사용하여 원소의 삽입 순서를 관리한다. 기존의 HashMap을 출력하면 입력 순서대로 출력되지 않지만 LinkedHashMap은 입력 순서대로 출력된다. 기본적으로 삽입 순서로 관리하지만 최근에 접근한 순서로 바꿀 수도 있다. 삽입 순서가 중요한 일부 상황에서 사용된다.
(3) TreeMap
레드 블랙 트리를 구현한 Map이다. 다양한 키가 필요할 때 아주 유용하고 키를 바탕으로 한 범위 검색에 효율적이다. 키 값으로 Map 일부를 처리해야 할 때 TreeMap이 좋은 선택이 될 수 있다.
3) Set 최적화
HashSet은 HashMap, TreeSet은 TreeMap으로 구성되어 있다. 따라서 성능 고려 사항은 Map과 거의 동일하다.
내부적으로 Set은 키를 원소, 값은 더미 객체의 레퍼런스를 넣어서 관리한다.
2. 도메인 객체
비즈니스 개념을 구현한 코드를 도메인 객체라고 한다. 도메인 객체는 대부분 타입 간 연관되어 있고(Order와 OrderItem 연관) 데이터는 스트링, 기본형 등의 단순 자료형이 많이 활용된다.
이러한 도메인 객체에 메모리 누수가 발생할 수 있는데 jmap과 VisualVM과 같은 GUI 툴에서 누수를 효과적으로 진단할 수 있다. 일반적으로 코어 JDK의 자료 구조가 메모리 점유량과 인스턴스 수가 높아야 하는데 도메인 객체가 점유량이 높다면 메모리 누수를 의심해 보아야 한다.
일반적으로 단명 객체가 제 때 GC에 의해 제거되지 못하고 테뉴어드로 올라간 경우 메모리 누수가 발생할 수 있다.
3. 종료화
자바 종료화는 객체가 사라질 때 객체의 리소스 소유권을 자동으로 내어주는 장치이다. 어떤 파일, 네트워크 소켓과 같은 리소스의 소유권은 항상 객체의 수명과 함께 하도록 묶어야 한다.
1) Deprecated된 finalize
finalize가 오버라이드 된 경우 GC가 이 객체는 특별히 처리한다. 이 객체는 GC 사이클 중 바로 회수되지 않으며 종료화 대상으로 등록되어 수명이 연장된다.
- 종료화 가능한 객체는 큐로 이동한다.
- 애플리케이션 스레드 재시작 후 별도의 종료화 스레드가 큐를 비우고 각 객체마다 finalize() 메서드를 실행한다.
- finalize()가 종료된 후 다음 사이클에서 수집된다.
이 경우 제거되어야 할 객체 임에도 최소 한 사이클 생존하며 테뉴어드 객체인 경우 상당히 긴 시간동안 살아남을 수 있다.
또 다른 문제점으로 finalize에서 예외가 발생하면 종료화 스레드에서 수행되기 때문에 애플리케이션 스레드에서는 이 예외를 감지할 수 없다.
2) try-with-resources
자바7 부터 추가된 try-with-resources 생성자를 이용하면 AutoCloseable 인터페이스를 구현한 객체는 자동으로 close() 메서드가 수행된다.
1
2
3
try (BufferedReader reader = new BufferedReader(new FileReader(File))) {
String FirstLine = reader.readLine();
}
해당 자바 코드는 바이트코드로 생성될 때 close 메서드가 invokevirtual로 호출되는 코드가 추가된다. finalize()와 기능은 비슷하지만 구현 방식이 달라 finalize()가 가지고 있었던 문제점을 해결할 수 있다.
- finalize는 JVM에서 기존 객체와 다른 특별한 방법(종료화 스레드)을 사용한다.
- try-with-resource는 단순히 바이트코드를 추가한다.
4. 메서드 핸들
invokedynamic(람다 메서드를 실행하는 명령어)는 실제로 어느 메서드를 호출할지 런타임 전까지 결정되지 않는다. 대신 인터프리터가 호출부를 실행하게 되면 부트스트랩 메서드(BSM)가 호출되고 BSM은 실제 메서드를 가리키는 객체를 반환한다.
메서드 핸들은 invokedynamic으로 호출되는 메서드를 나타낸 객체이다. 얼핏보면 리플렉션과 비슷하지만 리플렉션으로 할 수 없는 여러 기능을 갖추고 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//Reflection
// Method 객체 가져오기
Method method = Calculator.class.getMethod("add", int.class, int.class);
// 객체 생성 및 메서드 호출
Calculator calc = new Calculator();
int result = (int) method.invoke(calc, 10, 20);
//MethodHandle
// 메서드 시그니처 정의 (반환 타입, 매개변수 타입)
MethodType mt = MethodType.methodType(int.class, int.class, int.class);
// MethodHandle 검색
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodHandle mh = lookup.findVirtual(Calculator.class, "add", mt);
// 객체 생성 및 메서드 호출
Calculator calc = new Calculator();
int result = (int) mh.invokeExact(calc, 10, 20);
MethodHandle이 리플렉션과 비교하여 가지는 장점은 다음과 같다.
- MethodHandle은 안정된 불변 객체로 재활용, 캐싱할 수 있다.
- 룩업 컨텍스트를 사용하여 호출 시점에서 접근 가능한 메서드 및 필드 정보를 가지고 있어 프라이빗 메서드를 선택적으로 접근할 수 있다.
- MethodType을 사용하여 컴파일 타임에 타입 안정성을 확인할 수 있다.
2. lookup()을 호출한 클래스 내부라면 private을 호출할 수 있다. 반면에 lookup()을 클래스 외부에 호출한다면 private을 호출할 수 없기 때문에 보안성이 향상된다.
3. 리플렉션을 사용할 경우 컴파일러가 인자의 개수, 타입, 반환 타입을 체크할 수 없다. 만약에 method.invoke(calc, “a”, “b”)란 코드를 작성했다고 해도 컴파일 타임에 에러를 확인할 수 없다.
반면 MethodHandle 방식은 MethodType으로 컴파일 타임에 타입 검증을 할 수 있기 때문에 리플렉션보다 안전하다.
1
2
3
MethodType mt = MethodType(int.class, int.class, int.class);
...
int result = (int) mh.invokeExact(calc, "a", "b"); //컴파일 에러