운영체제 - IPC(InterProcess Communication)

요약
- IPC는 무엇인가요?
IPC는 협력 프로세스 사이에서 다른 프로세스와 통신을 할 수 있게 하는 운영체제 모델입니다. 협력 프로세스는 정보 공유와 계산 속도 향상 등의 이유로 다른 프로세스와 통신을 해야 합니다. 하지만 프로세스는 기본적으로 독립된 메모리 공간에서 실행됩니다. 따라서 다른 프로세스와 정보를 공유하기 위해 IPC라는 모델을 운영체제에서 제공합니다. IPC는 크게 Shared Memory 방식과 Message Passing 방식으로 구분할 수 있습니다.
- IPC의 Shared Memory 방식은 무엇인가요?
두 프로세스가 모두 접근할 수 있는 공용 메모리 공간을 할당합니다. 처음 setup 시 비용이 크지만 이후 데이터 공유할 때 비용은 Message Passing에 비해 적어 데이터를 자주 공유할 때 유리합니다. 하지만 Producer Consumer Problem에서 확인할 수 있듯 race condition을 막기 위해 추가적인 구현이 필요합니다.
- IPC의 Message Passing 방식은 무엇인가요?
send와 receive라는 시스템 콜을 사용하여 다른 프로세스에게 직접 메세지를 보내는 직접 통신 방식과 메일함을 이용하는 간접 통신 방식으로 구현할 수 있습니다. 메세지를 커널에 복사하고 커널의 메세지를 가져갈 때 다시 복사하는 과정을 거치므로 메세지의 수가 많아진다면 오버헤드가 발생할 수 있습니다.
서론
앞선 포스트에서 자식 프로세스를 이용한 멀티 프로세스 방법을 확인하였다. 자식 프로세스는 부모 프로세스와 별도의 자원을 사용하기 때문에 자원의 독립성이 유지된다.
이 자원의 독립성은 장점도 있지만 프로세스 간 공유해야 할 데이터가 있을 때 이를 전달하기 까다로워진다. 운영체제는 이를 위해 IPC란 모델을 제공하고 있다.
IPC(InterProcess Communication)
프로세스는 다른 프로세스와 통신 여부에 따라 독립 프로세스와 협력 프로세스로 나눌 수 있다. 우리가 주목해야 할 것은 협력 프로세스이다. 이 협력 프로세스는 다음과 같은 이유로 다른 프로세스에 영향을 주거나 받는다.
- 정보 공유 : 여러 프로세스가 동일한 정보에 관심을 둘 수 있으므로 이를 공유한다.
- 계산 속도 향상 : 하나의 일을 여러 프로세스가 수행하도록 나눈 후 멀티코어를 활용하여 병렬로 계산한다.
- 모듈성 : 시스템 기능을 별도의 프로세스로 분리한다.
- 편의성 : 사용자들이 한 번에 여러 작업을 할 수 있게 구성한다.
협력 프로세스 사이에서 다른 프로세스에 정보를 주거나 받을 수 있는 운영체제 모델이 바로 IPC이다.
크게 Shared Memory와 Message Passing 두 가지 방식이 존재한다.

Shared Memory
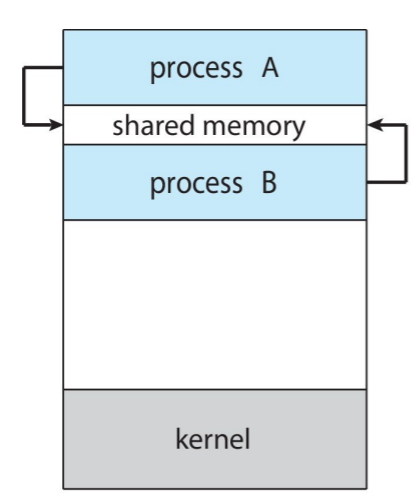
Shared Memory 방식은 여러 프로세스가 접근할 수 있는 공유 메모리 영역을 구축하여 정보를 주고 받는다. 여러 프로세스가 공유 메모리 영역 내 하나의 변수에 접근하면 여러 문제가 발생할 수 있다. 이 문제에 대한 자세한 설명과 해결 방법은 다음 포스트에서 설명한다.
Producer Consumer Problem
생산자(Producer)는 정보를 생산하고 소비자(Consumer)에서 이 정보를 소비한다. 이 정보를 공유 메모리에 저장하기 위해 버퍼 방식을 활용할 수 있다.
1
2
3
4
5
6
7
8
#define BUFFER_SIZE 10
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;
공유 메모리 공간은 한정되어 있으므로 생산자는 동시에 무한정 많은 정보를 생산할 수 없다. 따라서 Shared Memory 방식에서 정보를 저장하는 버퍼는 크기에 제한이 있는 bounded-buffer이다.
버퍼는 두 가지 포인터를 가진다. in은 생산자가 생산한 정보가 들어갈 위치를 가르키는 포인터이다. 생산자가 정보를 하나 생산하면 in은 1 증가한다. out은 소비자가 소비할 정보가 있는 위치를 가르키는 포인터이다. 소비자가 정보를 하나 소비하면 out은 1 증가한다.
Producer
bounded-buffer에서 생산자는 버퍼에 더 이상 넣을 공간이 없다면 정보를 생산할 수 없다.
1
2
3
4
5
6
7
item next_produced; //생산자가 생산한 정보
while (true) {
while(((in + 1) % BUFFER_SIZE) == out); //버퍼가 꽉 찬 상태이므로 대기
buffer[in] = next_produced; //버퍼에 생산한 정보를 넣음
in = (in + 1) % BUFFER_SIZE; //포인터 옮기기
}
여기서 버퍼는 circular array 구조를 가짐을 알 수 있다. in 포인터가 버퍼 배열의 마지막에 도달했다면 다시 처음부터 돌아가 생산한 정보를 저장한다(in = (in + 1) % BUFFER_SIZE). (in + 1) % BUFFER_SIZE == out은 circular array에서 in 다음 포인터가 out이므로 아직 소비자가 읽지 않은 정보란 뜻이다. 이 때 생산자가 정보를 계속 생산해버리면 소비자가 읽지 않은 정보를 덮어쓰게 된다. 따라서 생산자가 더 이상 정보를 생산할 수 없는 버퍼가 꽉 찬 상태이므로 소비자가 정보를 읽을 때까지 기다린다.
Consumer
1
2
3
4
5
6
item next_consumed; //소비자가 소비할 정보
while (true) {
while (in == out); //읽을 정보가 없는 상태
next_consumed = buffer[out]; //공유 메모리 버퍼에서 소비할 정보를 가져옴
out = (out + 1) % BUFFER_SIZE; //포인터 옮기기
소비할 정보가 없는 경우 생산자가 정보를 생산할 때까지 대기한다(in == out). 소비할 정보가 있다면 읽어들인 후 out 포인터를 옮긴다.
Producer Consumer Problem에서 왜 circular array를 활용할까?
왜 circular array를 활용하여 in과 out으로 포인터를 두 개 둘까? Producer가 정보를 생산하면 counter를 1 늘리고 Consumer가 정보를 소비하면 counter를 1 줄이는 식으로 구현할 수도 있을 텐데 말이다. counter가 5일 때 Producer와 Consumer가 동시에 생산하고 소비한다고 해보자. 우리의 상식으로는 counter가 여전히 5가 되어야 할 것 같다. 하지만 컴퓨터는 “동시에” 두가지 일을 처리할 수 없다.
동시에 들어와도 일은 순차적으로 처리되기 때문에 다음 그림과 같은 일이 일어난다.

counter의 결과는 4가 된다. 이는 여러 프로세스가 하나의 변수에 쓰기를 시도하기 때문에 일어나는 일이다. 이렇게 두 프로세스가 하나의 수에 동시에 쓰기 작업을 시도하면 발생하는 상황을 Race Condition이라고 한다. 따라서 하나의 포인터를 사용하는 방법은 피해야 한다.
Message Passing
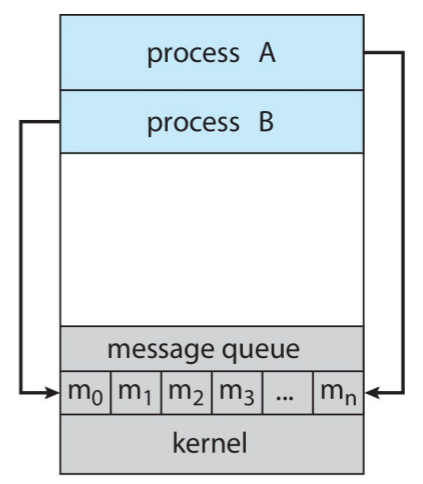
Message Passing의 경우 서로 공유하는 메모리 공간이 없다. 대신 프로세스 간 메세지 전달로 정보를 공유하게 된다. 프로세스 P와 Q가 서로 메세지를 전달하고 싶다면 아래 두가지 과정을 거쳐야 한다.
- 두 프로세스 사이에 통신 회선을 구축해야 한다.
- 이 후 메세지를 교환한다.
이 통신 회선을 어떻게 구축하고 메세지를 어떻게 전송하는지에 따라 Message Passing도 여러 방법으로 나눌 수 있다.
- 직접(Direct)/간접(Indirect)
- 동기(Synchronous)/비동기(asynchronous)
직접 통신(Direct Communication)
직접 통신은 데이터를 누구에게 보낼지 그리고 누구에게 받을지 명시해야 한다. 아래와 같은 연산으로 메세지를 주고 받을 수 있다.
- send(P, message) : 프로세스 P에게 메세지(데이터)를 보낸다.
- receive(Q, message) : 프로세스 Q에게 메세지를 받는다.
직접 통신의 통신 회선은 통신하려는 두 프로세스 사이에 단 하나의 회선이 자동으로 구축되는 특징을 가진다.
간접 통신(Indirect Communication)
프로세스에게 직접 메세지를 보내는 것이 아닌 우편함(mailbox)이라는 간접적인 매체를 통해 전송된다. 각 우편함은 고유한 id를 가지고 있어 프로세스가 어떤 메일함을 사용할 것인지 선택할 수 있다. 이 간접 통신 방법은 직접 통신과 달리 세 개 이상의 프로세스도 데이터를 공유할 수 있다.
- send(A, message) : 메일함 A에게 메세지를 보낸다.
- receive(A, message) : 메일함 A에게서 메세지를 받는다.
만약 하나의 프로세스가 메일함 A에게 메세지를 보내고 두 프로세스가 메일함 A에게 메세지를 받는다면 어떻게 될까? 둘 중 하나의 프로세스가 가져가는 대신 메세지를 보낸 프로세스는 어떤 프로세스가 가져가는 지 알고 있다.
동기화 여부
동기(Synchronous)와 비동기(Asynchronous), 블로킹(Blocking)과 논블로킹(Non Blocking)은 한 번쯤 들어보았을 것이다. 동기/비동기와 블로킹/논블로킹은 서로 다른 관심사이다. 따라서 비동기 블로킹과 같은 생소한 개념도 있지만 이번 포스트에서는 동기-블로킹(Sync-Blocking)과 비동기-논블로킹(Aasync-NonBlocking)만 알아보자.
- 동기-블로킹 방식 send : 메세지를 전송한 프로세스는 다른 프로세스가 메세지를 받을 때까지 기다린다.
- 동기-블로킹 방식 receive : 메세지를 받는 프로세스는 다른 프로세스가 메세지를 보낼 때까지 기다린다.
- 비동기-논블로킹 방식 send : 메세지를 전송한 프로세스는 바로 다음 작업을 수행한다.
- 비동기-논블로킹 방식 receive : 메세지를 받는 프로세스는 받을 메세지가 있으면 받은 후 바로 다음 작업을 수행한다. 만약 받을 수 있는 메세지가 없는 경우에도 기다리지 않고 바로 다음 작업을 수행한다.
Shared Memory와 Message Passing 비교
Shared Memory 방식과 Message Passing 방식을 비교하면 다음과 같이 정리할 수 있다.
성능
Message Passing은 하나의 메세지마다 두 번의 시스템 콜을 호출한다. 또한 메세지를 커널에 전송할 때 데이터가 한번 복사하고 메세지를 받아갈 때 데이터를 한번 복사하여 총 두번 복사된다. 따라서 메세지의 수가 많아지는 경우 오버헤드가 커질 수 있다. 반면 처음 setup시 오버헤드는 Shared Memory보다 작다.
Shared Memory는 처음 setup할 때 오버헤드가 크지만 메모리가 할당된 이후 데이터의 크기에 따른 패널티는 거의 없다. 따라서 데이터의 크기가 큰 경우 Shared Memory 방식이 유리하다.
동기 문제
Shared Memory는 Producer Consumer Problem에서 확인한 바와 같이 두 프로세스가 동시에 쓰기 작업을 시도하는 경우 이에 대한 처리가 까다롭다.
Message Passing 방식은 비동기-논블로킹 방식 send/receive를 사용하여 비교적 간편하게 이 문제를 회피할 수 있다.
커널 관여 여부
Shared Memory는 처음 공유 메모리 할당에만 관여하고 이후 두 프로세스가 할당된 공유 메모리를 바탕으로 정보를 교환한다.
Message Passing 방식은 프로세스가 메세지를 보내면 커널의 Message Queue에 전달된다. 이후 프로세스가 메세지를 받을 때 Message Queue에서 받는다.
이를 정리하면 Shared Memory 방식은 setup 비용이 크고 데이터 공유 비용은 적으므로 데이터 공유가 잦거나 크기가 큰 데이터를 공유할 때 유리하다. 하지만 동기 문제를 회피하기 까다롭다.
반면 Message Passing 방식은 setup 비용이 적고 데이터 공유 비용이 커 데이터 공유를 자주 하지 않는 경우 유리하다. 또한 동기 문제도 회피하기 쉽다는 장점이 있다.
IPC 시스템 예시
POSIX
유닉스/리눅스 계열인 POSIX는 Shared Memory 방식을 사용한다.
shm_open()시스템 콜으로 공유 메모리 객체를 생성한다.ftruncate()시스템 콜으로 메모리 객체의 크기를 할당할 수 있다.mmap()시스템 콜으로 공유 메모리 주소를 얻어 쓰고 읽을 수 있다.
Mach
Mac OS의 기반이 되는 Mach 커널은 Message Passing 방식을 사용한다.
- 메세지의 헤더에 sender의 포트와 receiver의 포트를 명시한다.
- sender에서
mach_msg()시스템 콜을 실행하여 메세지를 전송한다. - receiver에서
mach_msg()시스템 콜을 실행하여 메세지를 받는다.
Windows
ALPC(Advanced Local Procedure Call) 방식을 사용한다.
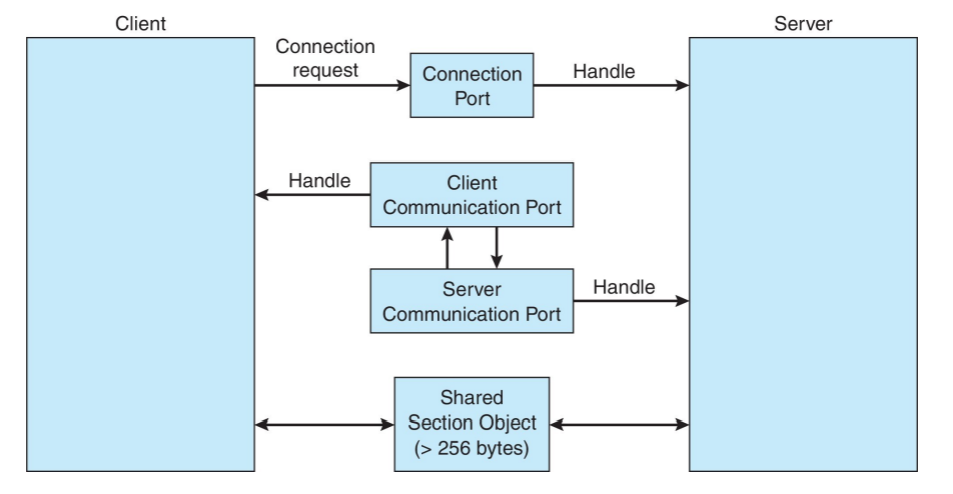
- 연결 포트를 통해 다른 프로세스와 연결을 요청한다.
- 데이터의 크기가 큰 경우 Shared Memory 방식으로 데이터를 공유한다.
- 데이터의 크기가 작은 경우 Message Passing 방식을 사용한다.
Pipes
두 프로세스 사이의 통신을 구현한다. Ordinary Pipes 방식과 Named Pipes 방식이 있다.
Ordinary Pipes
Windows는 이를 Anonymous Pipes라고도 부른다. 생산자는 데이터를 쓸 수만 있고 소비자는 데이터를 읽을 수만 있어 단방향 구조를 가진다. 통신하기 위해서 부모와 자식 프로세스 관계가 필요하다.
Named Pipes
통신하기 위해 부모-자식 관계가 필요 없어 여러 프로세스가 Named Pipe를 사용할 수 있다. 또한 양방향 구조이므로 Ordinary Pipes보다 더 강력하다.
Socket
Socket은 네트워크를 이용하여 다른 컴퓨터의 프로세스와 통신할 수 있다. Socket은 UDP 방식과 TCP 방식이 있는데 이와 관련한 자세한 내용은 추후에 알아볼 것이다.
RPC
LPC(Local Procedure Call) 방식은 하나의 컴퓨터에서 다른 프로세스와 통신한다면 RPC는 네트워크 상의 다른 컴퓨터의 프로세스와 통신할 수 있다. OS는 보통 client와 server 사이를 연결하는 matchmaker 서비스를 제공한다. 이를 통해 원격 컴퓨터에 존재하는 프로시저를 공유받을 수 있다.
결론
이렇게 3개의 포스트에 걸쳐 프로세스에 대해 알아보았다. 프로세스는 자원의 독립성을 보장하지만 그만큼 무겁다는 단점이 있다. 자식 프로세스를 생성하기 위해서는 부모 프로세스를 복사하는 만큼 잦은 자식 프로세스의 생성은 성능 저하 요소가 된다. 또한 프로세스의 전환(Context Switching)도 비용이 적지 않다.
다음 포스트에서는 프로세스보다 가벼운 쓰레드에 대해 알아볼 예정이다.
Reference
2022 1학기 운영체제 수업 자료
Operating System Concepts, 8th Edition. Abraham Silberschatz, Peter Baer Galvin, Greg Gagne. Wiley
https://blog.naver.com/and_lamyland/221177950390
https://w3.cs.jmu.edu/kirkpams/OpenCSF/Books/csf/html/IPCModels.html